ICS 184 : Database Systems
Assignment #1
Question 1
| Isolation is not guaranteed |
Two persons A and B share an account with an initial balance of $10,000. A and B happen to withdraw at the same time: A withdraws $100 and B withdraws $200. The final balance should be $9,700.
However, assume that concurrency is allowed and the following sequence of execution has been executed:
ReadA(10,000);
ReadB(10,000);
WriteB(9,800);
WriteA(9,900);
The final balance is $9,900. Clearly, lack of isolation can produce an incorrect result.
| Atomicity is not guaranteed |
Suppose I have a savings account (initial balance = 10,000) and a checking account (initial balance = 5,000). On April 1, 1999 when I was transferring $800 from my savings account to my checking account, a power failure occurred. As a result, the savings account was debited but the checking account was not credited (I lost $800! L ).
Consider the following sequence of execution:
Read(Savings, 10,000);
Read(Checking, 5,000);
Write(Savings, 9,200);
Power Failure…
The final balances: Savings = 9,200, Checking = 5,000, which are incorrect!
| Durability is not guaranteed |
Suppose I have a checking account of $5,000. Right after I successfully withdrew $300 at an ATM in Las Vegas, an earthquake occurred. I later found out that my account was not debited (the balance was still $5,000)
Since durability was not guaranteed, the new balance did not persist!
Question 2
| The size of the IRS database over the past 50 years: |
| On disks: 10 * 100,000,000 KB = 1,000 GB |
| On tapes: 49 * 10 * 100,000,000 KB = 49,000 GB |
| Average time to search for a given record: |
Number of
Records in 10M is: 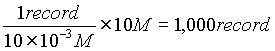 |
| So, it takes 1 sec to read in 1,000 records |
| It takes 1 sec to search for a record in the 1st 1000 records | |
| It takes 2 sec to search for a record in the 2nd 1000 records | |
| … | |
| It takes k sec to search for a record in the kth 1000 records |
Average access
time: 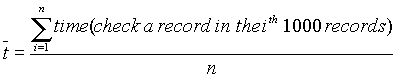 |
| There are 100,000,000 records on disk |
Therefore, 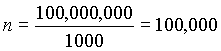 |
Question 3
| The cost of the given algorithm: |
| Records read from Employee file: 10,000 | |
| Records read from WorksOn file: 10,000 * 10,000 | |
| Records read from EmpWorksOn file: 10,000 | |
| Records read from Project file: 10 * 10,000 | |
| Records read
from EmpWorkOnProject file: 10,000 -------------------------- |
| TOTAL records read: 100,130,000 |
| Records written to EmpWorkOn file: 10,000 | |
| Records written
to EmpWorkOnProject file: 10,000 --------------- |
| TOTAL records written: 20,000 |
| Our more efficient algorithm |
while (!eof(Employee file))
{
read record E from Employee file;
if(E.dateOfBirth < 01/01/1920)
append record E to Before1920 file
}
while ( !eof (WorksOn file))
{
read a record W from WorksOn file;
while ( !eof (Project file))
{
read a record P from Project file;
if (P.projectName == "Mercury")
{
create a record of ME with:
ME.ssn = W.ssn;
Append record ME to MercuryEmp;
}
}
}
while ( !eof(Before1920 file))
{
read a record B from Before1920 file;
while ( !eof (MercuryEmp file))
{
read a record ME from MercuryEmp file;
if (B.ssn = ME.ssn)
print B.employeeName;
}
}
| Why is our algorithm more efficient? |
| Fewer number of read operations: |
| Read Employees file: 10,000 | |
| Read WorksOn file: 10,000 | |
| Read Project file: 10 * 10,000 | |
| Read MercuryEmp file: 10 * 1,000 | |
| Read Before1920
file:
10 --------------------------- |
� TOTAL records read: 130,010
| Fewer number of write operations: |
| Write to Before1920 file: 10 | |
| Write to
MercuryEmp file:
1,000 ------------------- |
� TOTAL write operations: 1010
Click [Here] for table of contents